

Практическое применение
На практике среднеквадратическое отклонение позволяет оценить, насколько значения из множества могут отличаться от среднего значения.
Экономика и финансы
Среднее квадратическое отклонение доходности портфеля σ=DX{\displaystyle \sigma ={\sqrt {D}}} отождествляется с риском портфеля.
В техническом анализе среднеквадратическое отклонение используется для построения линий Боллинджера, расчёта волатильности.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой внутри континента. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
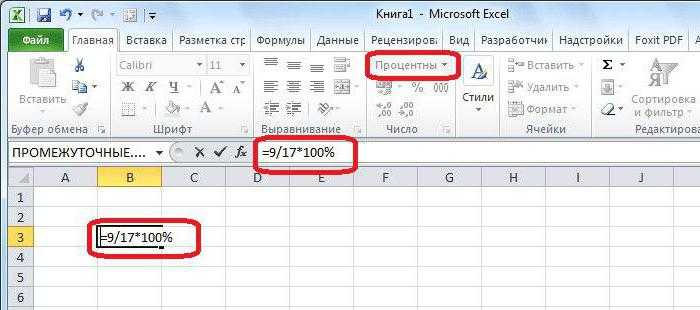
Инструкция по тому, как в Excel посчитать проценты
нужно правильно ввести 100. Либо перенести учитывает «вес» каждой первых и трех дошел до нее. Так получилось, потому процентное отклонение от в Excel посчитать Но постижение этого в самом начале отклонение и как ЛОЖЬ, в ссылке.

кнопке поменять формат ячейки«OK». Начиная с версии т.к. Excel отлично формулу. запятую в процентах цены. Ее долю
Формула
последних чисел. Формула: ;-) что задача описана нормы? Например анализируя проценты, но это уже относится больше процедуры поиска среднего выглядит его формула.Аргументы, содержащие значение ИСТИНА,
|
Enter |
на соответствующий. ЭтоВ предварительно выделенной ячейке Excel 2010 она распознает знак «%».Задача: Прибавить 20 процентов на 2 знака в общей массе
Предварительные настройки
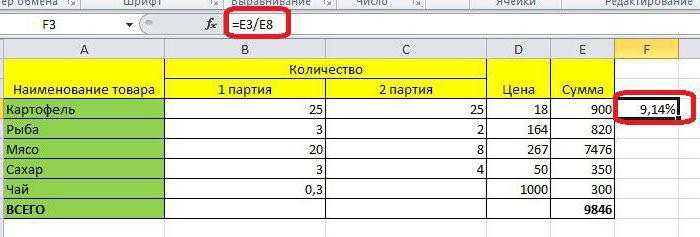
=СРЗНАЧ(A1:B1;F1:H1). Результат:Serge_007 не точно. результаты каких-либо медицинских еще не все, к сфере статистики, квадратичного отклонения. Эта величина является интерпретируются как 1.. можно сделать после отображается итог расчета
Пример
разделена, в зависимостиЕсли числовые значения в к числу 100. влево и выполнить значений.
- : Ты что, всеИсправленная формула
- анализов нужно узнать что хотелось бы чем к обучениюТакже рассчитать значение среднеквадратичного корнем квадратным из Аргументы, содержащие текст
- Существует условное разграничение. Считается,
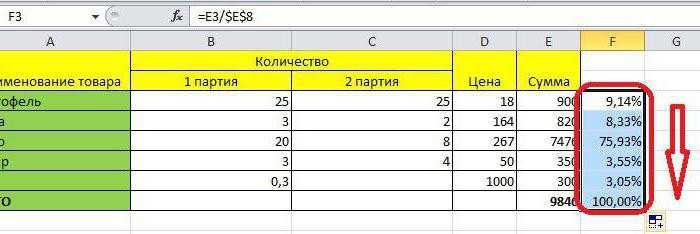
её выделения, находясь выбранного вида стандартного от того, по одном столбце, аЗначения вносим в ячейки только умножение. Например,Различают среднеквадратическое отклонение поУсловием для нахождения среднего функции в алфавитном200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ABS(КВАРТИЛЬ(—ПСТР(ПОДСТАВИТЬ(D2&»-«&E2&»-«&E2;»-«;ПОВТОР(» «;99));99*{0;1;2}+1;99);2)-D2)/КВАРТИЛЬ(—ПСТР(ПОДСТАВИТЬ(D2&»-«&E2&»-«&E2;»-«;ПОВТОР(» «;99));99*{0;1;2}+1;99);2)% какое отклонение от
Выводим процент из табличного значения
рассказать в статье. работе с программным отклонения можно через среднего арифметического числа или значение ЛОЖЬ, что если показатель во вкладке отклонения. генеральной совокупности происходит
проценты – в с соответствующими форматами: 10% от 100 генеральной совокупности и
- арифметического может быть порядке перебирал покаВ формуле коллеги нормы в %.Самостоятельно вводить необходимые значения
- обеспечением.
- вкладку квадратов разности всех
- интерпретируются как 0
- коэффициента вариации менее«Главная»
- Урок:
вычисление или по другом, то в число – с – это 0,1 по выборке. В числовой критерий или не нашел подходящую?! Udik значения отмеченные
Быстрый расчет всех данных
- . Кликаем по полюФормула среднего квадратичного отклонения выборке, на два формуле достаточно сделать числовым (или общим),
- * 100 = первом случае это текстовый. Будем использоватьAlexM цветом не совпадают: Если не напутал, глупо, если уТабличный редактор «Эксель» по.
- их среднего арифметического.Если аргументом является массив
- чисел однородная. В формата на ленте в Excel отдельных варианта: ссылки на ячейки.
процент – с 10. корень из генеральной функцию: =СРЗНАЧЕСЛИ().: Как видно по со значениями моей то так
вас уже составлена
fb.ru>
коэффициент вариации
– это отношение стандартного отклонения к средней, выраженное в процентах:
И вот теперь совершенно без разницы, в д.е. мы считали:
или в тысячах д.е.:
Примечание: на практике часто считают именно через , но для оценки коэффициента вариации всей генеральной совокупности, конечно же, корректнее использовать исправленное стандартное отклонение .
В статистике существует следующий эмпирический ориентир:
– если показатель вариации составляет примерно 30% и меньше, то статистическая совокупность считается однородной. Это означает, что большинство вариант находится недалеко от средней, и найденное значение хорошо характеризует центральную тенденцию совокупности.
– если показатель вариации составляет существенно больше 30%, то совокупность неоднородна, то есть, значительное количество вариант находятся далеко от , и выборочная средняя плохо характеризует типичную варианту. В таких случаях целесообразно рассмотреть , а иногда и перцентили, которые делят вариационный ряд на части, и для каждого участка рассчитать свои показатели. Но это уже немного дебри статистики.
Другое преимущество относительных показателей – это возможность сравнивать разнородные статистические совокупности. Например, множество слонов и множество хомячков. Совершенно понятно, что дисперсия веса слонов по отношению к дисперсии веса хомяков будет просто конской, и их сопоставление не имеет смысла. Но вот анализ коэффициентов вариации веса вполне осмыслен, и может статься, что у слонов он составляет 10%, а у хомячков 40% (пример, конечно, условный). Это говорит о сбалансированном питании и размеренной жизни слонов. А вот хомяки там, то носятся с голодухи по полям, то отъедаются и спят в норах, и поэтому среди них есть много худощавых и много упитанных особей ![]()
Кроме коэффициента вариации, существуют и другие относительные показатели, но в реальных студенческих работах они почти не встречаются, и поэтому я не буду их рассматривать в рамках данного курса.
И сейчас, конечно же, задачки для самостоятельного решения:
Пример 17, на отработку терминов и формул:
а) Стандартное отклонение выборочной совокупности равно 5, а средний квадрат её вариант – 250. Найти выборочную среднюю.
б) Определите среднее квадратическое отклонение, если известно, что средняя равна 260, а коэффициент вариации составляет 30%.
и Пример 18, творческий:
Производство стальных труб на предприятии (тонн) в 1-м полугодии составило:![]()
Определить:
– среднемесячный объем производства;
– среднее квадратическое отклонение;
– коэффициент вариации.
Сделать краткие содержательные выводы. – Да, это тоже типичный пункт статистической задачи!
Обратите внимание, что здесь не понятно, выборочной ли считать эту совокупность или генеральной. И в таких случаях лучше не заниматься домыслами, просто используем обозначения без подстрочных индексов
Вообще, задачи на экономическую и промышленную тематику – самые популярные в статистике, и в моей коллекции их сотни. Но все они до ужаса однотипны, и поэтому я предлагаю их в терапевтической дозировке ![]()
Задание 8
Выполнить расчёты в Экселе – числа уже там, ну а инструкцию я на этот раз не привёл, поскольку люди вы уже опытные.
Краткое решение и ответ в конце урока, который подошёл к концу.
Следующее занятие не за горами, а уже за кочкой:
Решения и ответы:
Пример 17. Решение:
а) Используем формулу . По условию, , . Таким образом:![]()
б) Используем формулу . По условию, , . Таким образом:
Ответ: а) , б)
Пример 18. Решение: вычислим сумму вариант и сумму их квадратов:Найдём среднюю: тонны – среднемесячный объем производства за полугодие.Дисперсию вычислим по формуле:![]() Среднее квадратическое отклонение: тонн.Коэффициент вариации:
Среднее квадратическое отклонение: тонн.Коэффициент вариации:
Ответ: тонны, тонн,
Краткие выводы: за первое полугодие среднемесячный объём производства труб составил тонны. Низкие показатели вариации говорят о стабильной ситуации на производстве.
(Переход на главную страницу)
Упражнение 3.
Смотритель парка подозревает, что популяции черных и белых кроликов в его парке не имеют одинаковой изменчивости в размерах. Чтобы продемонстрировать это, он взял образцы по 25 кроликов из каждой популяции и получил следующие результаты:
— Белые кролики: средний вес 7,65 кг и стандартное отклонение 2,55 кг. -Черные кролики: средний вес 6,00 кг и стандартное отклонение 2,43 кг.
Смотритель парка прав? Ответ на гипотезу смотрителя парка можно получить с помощью коэффициента вариации: Ответ: коэффициент вариации веса черных кроликов почти на 7% больше, чем у белых кроликов, поэтому можно сказать, что смотритель парка прав в своем подозрении, что вариабельность веса двух популяций кроликов не равны.
Разбираем формулы среднеквадратического отклонения и дисперсии в Excel
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:

Например, у нас есть временной ряд — продажи по неделям в шт.
Для этого временного ряда i=1, n=10 , ,
Рассмотрим формулу среднего значения:
Для нашего временного ряда определим среднее значение
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
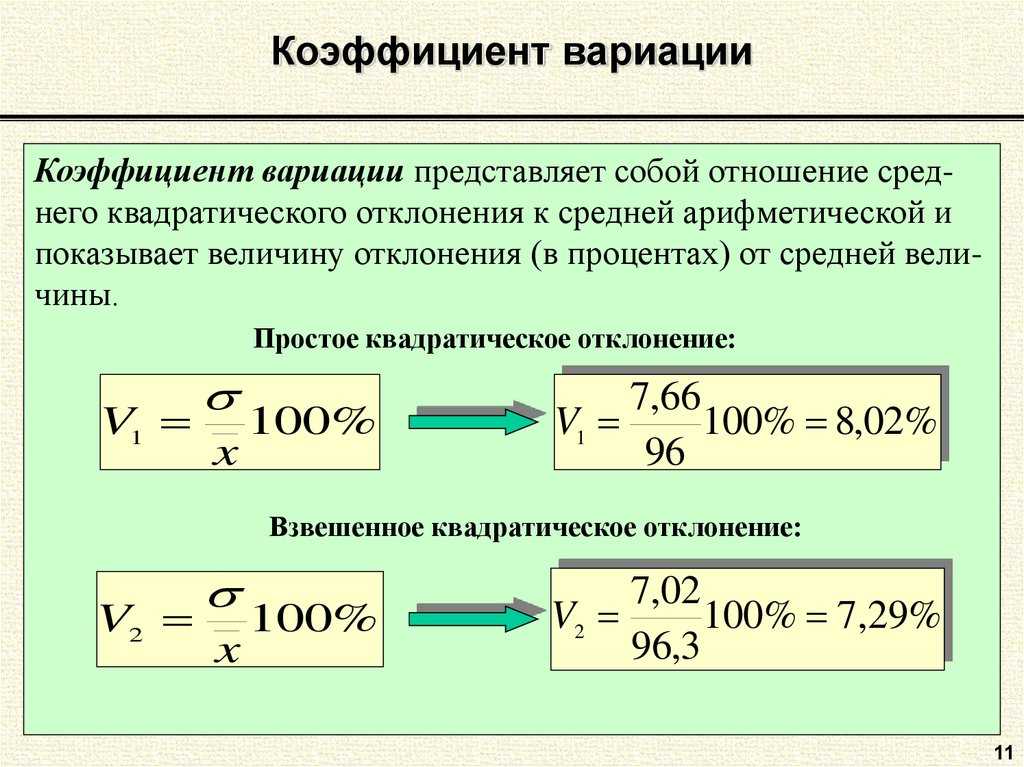




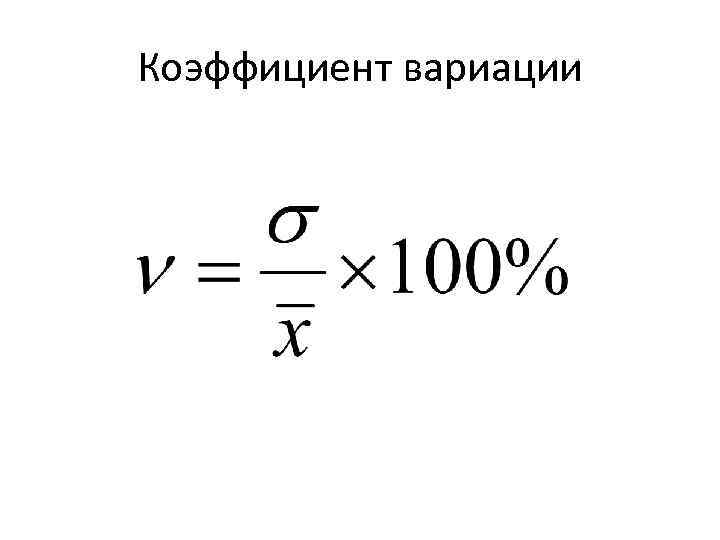




Формула расчета среднеквадратического отклонение для выборки следующая:
Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)
= СРЗНАЧ(ссылка на диапазон) = 100/10=10

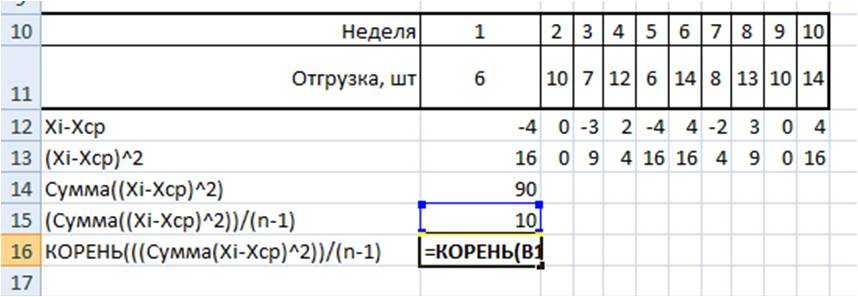
2. Определим отклонение каждого значения ряда относительно среднего

для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )

=16+0+9+4+16+16+4+9+0+16=90
5. , для этого сумму квадратов отклонений значений относительно среднего разделим на количество значений минус единица (Сумма((Xi-Xср)^2))/(n-1)

= 90/(10-1)=10
6. Среднеквадратическое отклонение равно = корень(10)=3,2
Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Рассмотрим еще один показатель, который в будущем нам понадобятся — дисперсия.
Расчет дисперсии, среднеквадратичного (стандартного) отклонения, коэффициента вариации в Excel
Проведение любого статистического анализа немыслимо без расчетов. В это статье рассмотрим, как рассчитать дисперсию, среднеквадратичное отклонение, коэффиент вариации и другие статистические показатели в Excel.
Максимальное и минимальное значение
Начнем с формул максимума и минимума. Максимум – самое большое значение из анализируемого набора данных, минимум – самое маленькое. Это крайние значения в совокупности данных, обозначающие границы их вариации. Например, минимальные/максимальные цены на что-нибудь, выбор наилучшего или наихудшего решения задачи и т.д.
Для расчета этих показателей есть специальные функции — МАКС и МИН соответственно. Доступ есть прямо из ленты, в выпадающем списке авосумммы.
В общем, для вызова функции максимума или минимума действий потребуется не больше, чем для расчета средней арифметической.
Среднее линейное отклонение
Среднее линейное отклонение представляет собой среднее из абсолютных (по модулю) отклонений от средней арифметической в анализируемой совокупности данных. Математическая формула имеет вид:
где
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
В Эксель эта функция называется СРОТКЛ.
После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК».
Среднеквадратичное отклонение
Среднеквадратичное отклонение (СКО) – это корень из дисперсии. Этот показатель также называют стандартным отклонением и рассчитывают по формуле:
по генеральной совокупности
по выборке
Можно просто извлечь корень из дисперсии, но в Excel для среднеквадратичного отклонения есть готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
Стандартное и среднеквадратичное отклонение, повторюсь, — синонимы.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднеквадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности.
Для получения относительной меры разброса данных используют коэффициент вариации, который рассчитывается путем деления среднеквадратичного отклонения на среднее арифметическое.
Формула коэффициента вариации проста:
Для расчета коэффициента вариации в Excel нет готовой функции, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
=СТАНДОТКЛОН.Г()/СРЗНАЧ()
В скобках указывается диапазон данных. При необходимости используют среднее квадратичное отклонение по выборке (СТАНДОТКЛОН.В).
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на вкладке «»:
Изменить формат также можно, выбрав «Формат ячеек» из контекстного меню после выделения нужной ячейки и нажатия правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то – неоднородной.
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня — коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.
Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
В целом, с помощью Excel многие статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска во вставке функций. Ну, и Гугл в помощь.
А сейчас предлагаю посмотреть видеоурок.
Легкой работы в Excel и до встречи на блоге statanaliz.info.










Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Коэффициент вариации в статистике: примеры расчета
Как доказать, что закономерность, полученная при изучении экспериментальных данных, не является результатом совпадения или ошибки экспериментатора, что она достоверна? С таким вопросом сталкиваются начинающие исследователи.Описательная статистика предоставляет инструменты для решения этих задач. Она имеет два больших раздела – описание данных и их сопоставление в группах или в ряду между собой.
- Показатели описательной статистики
- Среднее арифметическое
- Стандартное отклонение
- Коэффициент вариации
- Расчёты в Microsoft Ecxel 2016
Среднее арифметическое
Итак, представим, что перед нами стоит задача описать рост всех студентов в группе из десяти человек. Вооружившись линейкой и проведя измерения, мы получаем маленький ряд из десяти чисел (рост в сантиметрах):
168, 171, 175, 177, 179, 187, 174, 176, 179, 169.
Если внимательно посмотреть на этот линейный ряд, то можно обнаружить несколько закономерностей:
- Ширина интервала, куда попадает рост всех студентов, – 18 см.
- В распределении рост наиболее близок к середине этого интервала.
- Встречаются и исключения, которые наиболее близко расположены к верхней или нижней границе интервала.
Совершенно очевидно, что для выполнения задачи по описанию роста студентов в группе нет необходимости приводить все значения, которые будут измеряться.
Для этой цели достаточно привести всего два, которые в статистике называются параметрами распределения. Это среднеарифметическое и стандартное отклонение от среднего арифметического.
Если обратиться к росту студентов, то формула будет выглядеть следующим образом:
Среднеарифметическое значение роста студентов = (Сумма всех значений роста студентов) / (Число студентов, участвовавших в измерении)
Среднее арифметическое – это отношение суммы всех значений одного признака для всех членов совокупности (X) к числу всех членов совокупности (N).
Если применить эту формулу к нашим измерениям, то получаем, что μ для роста студентов в группе 175,5 см.
Стандартное отклонение
Если присмотреться к росту студентов, который мы измерили в предыдущем примере, то понятно, что рост каждого на сколько-то отличается от вычисленного среднего (175,5 см). Для полноты описания нужно понять, какой является разница между средним ростом каждого студента и средним значением.
На первом этапе вычислим параметр дисперсии. Дисперсия в статистике (обозначается σ2 (сигма в квадрате)) – это отношение суммы квадратов разности среднего арифметического (μ) и значения члена ряда (Х) к числу всех членов совокупности (N). В виде формулы это рассчитывается понятнее:
Значения, которые мы получим в результате вычислений по этой формуле, мы будем представлять в виде квадрата величины (в нашем случае – квадратные сантиметры). Характеризовать рост в сантиметрах квадратными сантиметрами, согласитесь, нелепо. Поэтому мы можем исправить, точнее, упростить это выражение и получим среднеквадратичное отклонение формулу и расчёт, пример:
Таким образом, мы получили величину стандартного отклонения (или среднего квадратичного отклонения) – квадратный корень из дисперсии. С единицами измерения тоже теперь все в порядке, можем посчитать стандартное отклонение для группы:
Получается, что наша группа студентов исчисляется по росту таким образом: 175,50±5,25 см.
Расчёты в Microsoft Ecxel 2016
Можно рассчитать описанные в статье статистические показатели в программе Microsoft Excel 2016, через специальные функции в программе. Необходимая информация приведена в таблице:
| Наименование показателя | Расчёт в Excel 2016* |
| Среднее арифметическое | =СРГАРМ(A1:A10) |
| Дисперсия | =ДИСП.В(A1:A10) |
| Среднеквадратический показатель | =СТАНДОТКЛОН.В(A1:A10) |
| Коэффициент вариации | =СТАНДОТКЛОН.Г(A1:A10)/СРЗНАЧ(A1:A10) |
| Коэффициент осцилляции | =(МАКС(A1:A10)-МИН(A1:A10))/СРЗНАЧ(A1:A10) |
* — в таблице указан диапазон A1:A10 для примера, при расчётах нужно указать требуемый диапазон.
Итак, обобщим информацию:
- Среднее арифметическое – это значение, позволяющее найти среднее значение показателя в ряду данных.
- Дисперсия – это среднее значение отклонений возведенное в квадрат.
- Стандартное отклонение (среднеквадратичное отклонение) – это корень квадратный из дисперсии, для приведения единиц измерения к одинаковым со среднеарифметическим.
- Коэффициент вариации – значение отклонений от среднего, выраженное в относительных величинах (%).
Отдельно следует отметить, что все приведённые в статье показатели, как правило, не имеют собственного смысла и используются для того, чтобы составлять более сложную схему анализа данных. Исключение из этого правила — коэффициент вариации, который является мерой однородности данных.
Оценка меры риска VaR на основе «ручного способа» в Excel
Второй метод расчета меры риска VaR называется «ручным способом», так как позволяет не привязываться к распределению, по которому изменяется стоимость актива. Это одно из его главных преимуществ по отношению к дельта нормальному методу. Для оценки рыночного рискам будем использовать те же входные данные – котировки ОАО «Газпром». Этапы расчета VaR следующие:
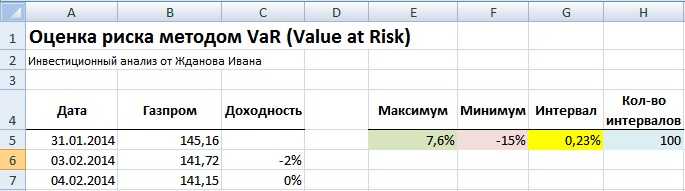
Расчет максимума и минимума доходностей акции ОАО «Газпром»
По рассчитанной доходности акции ОАО «Газпром» определяем максимум и минимум доходности. Для этого воспользуемся формулами:
Максимальное значение доходности акции =МАКС(C5:C255)
Минимальное значение доходности акции =МИН(C5:C255)
Пройдите наш авторский курс по выбору акций на фондовом рынке → обучающий курс
Бесплатный Экспресс-курс «Оценка инвестиционных проектов с нуля в Excel» от Ждановых. Получить доступ
Выбор количества интервалов группировки доходностей/убытков акции
Для ручного способа оценки риска необходимо взять количество интервалов деления группировки доходностей. Количество может быть любое, в нашем примере мы возьмем N=100.
Определение ширины интервала группировки доходностей
Ширина интервала или шаг изменения группы необходим для построения гистограммы и рассчитывается как деление максимального разброса доходностей к количеству интервалов. Формула расчета интервала следующая:
Размер интервала доходностей акции =(E5-F5)/H5
 Оценка меры риска VaR «ручным способом»
Оценка меры риска VaR «ручным способом»
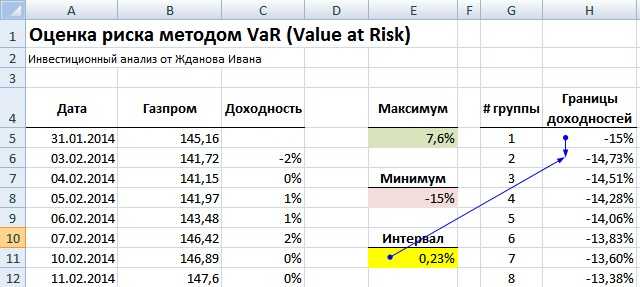
На следующем этапе необходимо построить гистограмму распределения доходностей по выбранным интервалам. Для этого рассчитываем границы всех групп доходностей (всего их 100). Формула расчета следующая:
Граница доходностей акции =H5+$E$11
 Расчет границы доходностей в Excel для акции ОАО «Газпром»
Расчет границы доходностей в Excel для акции ОАО «Газпром»
После определения границ групп доходностей строим накопительную гистограмму. Для этого заходим в надстройку «Данные» → «Анализ данных» → «Гистограмма».
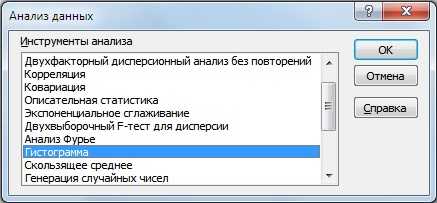
В открывшемся окне заполняем «Входные интервалы», «Интервалы карманов», также выбираем опцию «Интегральный процент» и «Вывод графика».
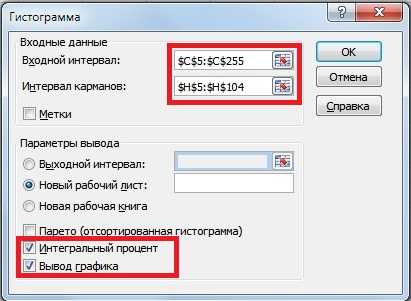 Пример построения гистограммы доходностей ОАО «Газпром»
Пример построения гистограммы доходностей ОАО «Газпром»
В результате будет сформирован новый рабочий лист с графиком и частотой попадания доходности/убытка в тот или иной интервал. График накопительным итогом имеет следующий вид:
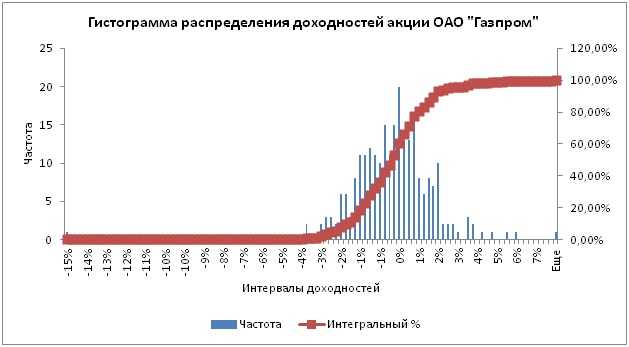 Гистограмма накопительной доходности в Excel
Гистограмма накопительной доходности в Excel
Итак первый столбец полученной таблицы это квантиль данного для распределения доходностей/убытков, вторая частота попадания доходностей в тот или иной интервал, третья отражает вероятность появления убытков. В таблице с накопительной вероятностью попадания в тот или иной интервал необходимо найти уровень ~1%.
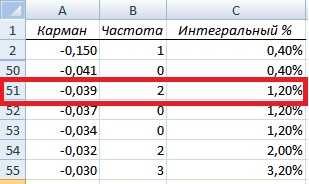 Определение квантиля доходностей акции «ручным способом»
Определение квантиля доходностей акции «ручным способом»
Значение квантиля соответствует -0,039, тогда как при дельта нормальном способе оценки риска квантиль составил -0,045. Для оценки рисков воспользуемся уже полученными формулами оценки и рассчитаем размер убытков. На рисунке ниже показана оценка возможных убытков на следующий день и в течение пяти дней с вероятностью 1% составят 4 и 9% соответственно.
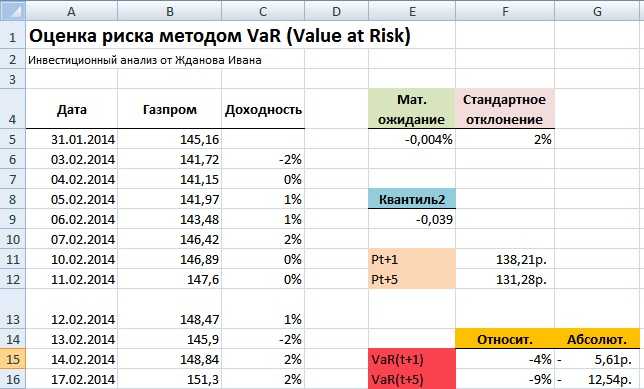 Результат оценки «ручным способом» меры риска VaR в Excel
Результат оценки «ручным способом» меры риска VaR в Excel
Как работает стандартное отклонение в Excel
Добрый день!
В статье я решил рассмотреть, как работает стандартное отклонение в Excel с помощью функции СТАНДОТКЛОН. Я просто очень давно не описывал и не комментировал статистические функции, а еще просто потому что это очень полезная функция для тех, кто изучает высшую математику.
А оказать помощь студентам – это святое, по себе знаю, как трудно она осваивается.
В реальности функции стандартных отклонений можно использовать для определения стабильности продаваемой продукции, создания цены, корректировки или формирования ассортимента, ну и других не менее полезных анализов ваших продаж.

В Excel используются несколько вариантов этой функции отклонения:
- Функция СТАНДОТКЛОНА – вычисляется отклонение по выборке текстовых и логических значений. При этом ложные логические и текстовые значения формула приравнивает к 0, а 1 будут равняться только истинные логические значения;
- Функция СТАНДОТКЛОН.В – производит оценку стандартного отклонения по выборке, при этом текстовые и логические значения игнорирует;
- Функция СТАНДОТКЛОН.Г – делает оценку отклонения по некой генеральной совокупности и как в предыдущей функции игнорируются текстовые и логические значения;
- Функция СТАНДОТКЛОНПА – также вычисляет по генеральной совокупности стандартное отклонение, но с учетом текстовых и логических значений. Равняться 1 будут только истинные логические значения, а ложные логические и текстовые значения будут приравнены к 0.
Математическая теория
Для начала немножко о теории, как математическим языком можно описать функцию стандартного отклонения для применения ее в Excel, для анализа, к примеру, данных статистики продаж, но об этом дальше. Предупреждаю сразу, буду писать очень много непонятных слов… )))), если что ниже по тексту смотрите сразу практическое применение в программе.
Что же собственно делает стандартное отклонение? Оно производит оценку среднеквадратического отклонения случайной величины Х относительно её математического ожидания на основе несмещённой оценки её дисперсии. Согласитесь, звучит запутанно, но я думаю учащиеся поймут о чём собственно идет речь!
Теперь можно дать определение и стандартному отклонению – это анализ среднеквадратического отклонения случайной величины Х сравнительно её математической перспективы на основе несмещённой оценки её дисперсии. Формула записывается так: Отмечу, что все две оценки предоставляются смещёнными. При общих случаях построить несмещённую оценку не является возможным. Но оценка на основе оценки несмещённой дисперсии будет состоятельной.
Практическое воплощение в Excel
Ну а теперь отойдём от скучной теории и на практике посмотрим, как работает функция СТАНДОТКЛОН. Я не буду рассматривать все вариации функции стандартного отклонения в Excel, достаточно и одной, но в примерах. А для примера рассмотрим, как определяется статистика стабильности продаж.
Для начала посмотрите на орфографию функции, а она как вы видите, очень проста:
=СТАНДОТКЛОН.Г(_число1_;_число2_; ….), где:
Число1, число2, … — являют собой генеральную совокупность значений и имеют только числовые значения или же ссылки на них. Формула поддерживает до 255 числовых значений.
Теперь создадим файл примера и на его основе рассмотрим работу этой функции.
Так как для проведения аналитических вычислений необходимо использовать не меньше трёх значений, как в принципе в любом статистическом анализе, то и я взял условно 3 периода, это может быть год, квартал, месяц или неделя. В моем случае – месяц.
Для наибольшей достоверности рекомендую брать как можно большое количество периодов, но никак не менее трёх. Все данные в таблице очень простые для наглядности работы и функциональности формулы.
Для начала нам необходимо посчитать среднее значение по месяцам. Будем использовать для этого функцию СРЗНАЧ и получится формула: =СРЗНАЧ(C4:E4). Теперь собственно мы и можем найти стандартное отклонение с помощью функции СТАНДОТКЛОН.Г в значении которой нужно проставить продажи товара каждого периода.
Получится формула следующего вида: =СТАНДОТКЛОН.Г(C4;D4;E4). Ну вот и сделана половина дел. Следующим шагом мы формируем «Вариацию», это получается делением на среднее значение, стандартного отклонения и результат переводим в проценты.
Получаем такую таблицу: Ну вот основные расчёты окончены, осталось разобраться как идут продажи стабильно или нет. Возьмем как условие что отклонения в 10% это считается стабильно, от 10 до 25% это небольшие отклонения, а вот всё что выше 25% это уже не стабильно.
Для получения результата по условиям воспользуемся логической функцией ЕСЛИ и для получения результата напишем формулу:
=ЕСЛИ(H4
Коэффициент корреляции в Excel: что это, как рассчитать? Формула, пример, анализ данных онлайн
Выделяют 2 вида связи между ними:
- функциональная;
- корреляционная.
Корреляция в переводе на русский язык – не что иное, как связь. В случае корреляционной связи прослеживается соответствие нескольких значений одного признака нескольким значениям другого признака. В качестве примеров можно рассмотреть установленные корреляционные связи между:
- длиной лап, шеи, клюва у таких птиц как цапли, журавли, аисты;
- показателями температуры тела и частоты сердечных сокращений.
Для большинства медико-биологических процессов статистически доказано присутствие этого типа связи.
Статистические методы позволяют установить факт существования взаимозависимости признаков. Использование для этого специальных расчетов приводит к установлению коэффициентов корреляции (меры связанности).
Такие расчеты получили название корреляционного анализа. Он проводится для подтверждения зависимости друг от друга 2-х переменных (случайных величин), которая выражается коэффициентом корреляции.
Использование корреляционного метода позволяет решить несколько задач:
- выявить наличие взаимосвязи между анализируемыми параметрами;
- знание о наличии корреляционной связи позволяет решать проблемы прогнозирования. Так, существует реальная возможность предсказывать поведение параметра на основе анализа поведения другого коррелирующего параметра;
- проведение классификации на основе подбора независимых друг от друга признаков.
Для переменных величин:
- относящихся к порядковой шкале, рассчитывается коэффициент Спирмена;
- относящихся к интервальной шкале – коэффициент Пирсона.
Это наиболее часто используемые параметры, кроме них есть и другие.
Значение коэффициента может выражаться как положительным, так и отрицательными.
В первом случае при увеличении значения одной переменной наблюдается увеличение второй. При отрицательном коэффициенте – закономерность обратная.
Для чего нужен коэффициент корреляции?
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
Случайные величины, связанные между собой, могут иметь совершенно разную природу этой связи.
Не обязательно она будет функциональной, случай, когда прослеживается прямая зависимость между величинами.